Crazy workarounds! Yes, pretty much sums up the whole process. When designing fonts supporting writing systems (popularly referred to as alphabets, though most are not) that are not yet encoded into Unicode, one tends to use unconventional methods to get things working. True story. Here is an unorthodox method I personally applied during the process of creating a font for the Mwangwego script.
First, to be all on the same page, let me clarify what the Unicode is and it’s role in the process:
The Unicode Consortium enables people around the world to use computers in any language, by providing freely-available specifications and data to form the foundation for software internationalization in all major operating systems, search engines, applications, and the World Wide Web. An essential part of this purpose is to standardize, maintain, educate and engage academic and scientific communities, and the general public about, make publicly available, promote, and disseminate to the public a standard character encoding that provides for an allocation for more than a million characters.[1]
Summarized, everyone in the world should be able to use their own language on phones and computers. The Unicode Consortium helps make that possible by standardizing the world’s writing systems…and emoji.

Mwangwego script, is one of the writing systems not yet encoded into the Unicode standard, meaning it can’t be displayed on computers, smartphones & the World Wide Web, as shown above. Problem. The purpose of this font is to enable people, mainly educators, designers, and linguists, to create teaching, documentation & awareness material to keep the writing system alive in the digital age. These will also be helpful submissions to accelerate the Unicode encoding process, functionality then is important considering the target group mentioned earlier.
![A repertoire of the vowel marks [e i o u] connected to the base character ‘ba’](https://prototyprio.gumlet.io/wp-content/uploads/2022/03/pic3a.jpeg?w=2880&q=75&format=auto&compress=true&dpr=1)
The structure of the Mwangwego script helped establish the method I used to create a functional font. The script is an abugida, vowels are added to the base characters (consonants) which have an inherent vowel ‘a’ to form syllables. Spacing consonant modifiers & diacritics are also used to extend the consonants.


The solution? Assigning the Mwangwego base characters to the Latin character code-points. Yes, that’s what I did. The idea was pairing similar looking consonant bases with their Latin counterparts, for example:
- ba > b
- cha > c
- da > d
- e > e (vowel)
- fa > f
This placement makes it easy to type using the usual Qwerty keyboard.
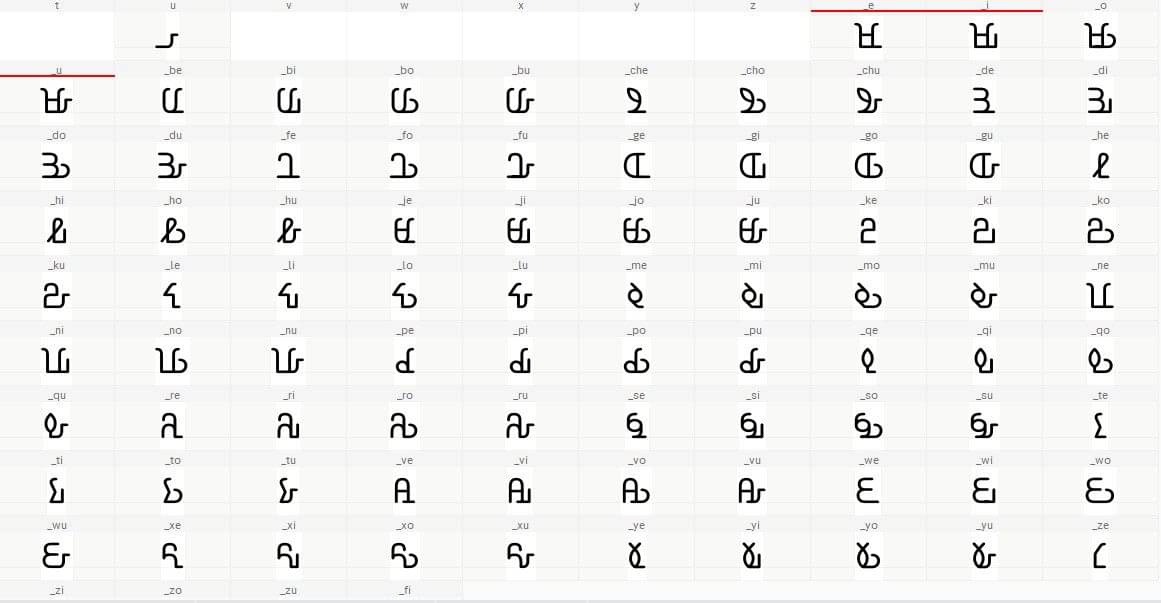
To cater for other syllables, those formed by adding[e i o u ] vowels, I designed composite forms of each syllable & individually assigned them to custom glyphs. This enabled me to write rlig (Required Ligutures) OpenType features to influence the syllable shaping behavior:
The ‘rlig’ (Required Ligatures) OpenType feature replaces a sequence of glyphs with a single glyph. The feature is widely supported and it is usually automatically enabled in most text editing & publishing applications, making it suitable for the intended usage. In our case, it will be replacing the sequence of glyphs ‘S & i’ [base character sa + vowel i] with a single glyph ‘_si’ [syllable si]. Further demonstrating, to type my name ‘Tapiwa’, you would tap ‘T’ on the keyboard to display the syllable ‘Ta’, tap ‘P i’ to display syllable ‘pi’ and ‘W’ to get the syllable ‘wa’…et voila! Tapiwa is displayed, in the Mwangwego script.
The OpenType features I wrote looked something like this:
feature rlig {
sub C e by _che;
sub C i by _chi;
sub C o by _cho;
sub C u by _chu;
sub D e by _da;
sub D i by _di;
sub D o by _do;
sub D u by _du;
…
…
…
To then cater for the syllables, I wrote rlig OpenType features so that the desired syllable will be displayed. For example if I want to type my name "Tapiwa"…pressing T will display the syllable "Ta", P i will display "pi" and "W" will display the syllable "wa"…et voila! pic.twitter.com/pm3ChiMN1L
— Tapiwanashe S. Garikayi (@Sebastiangary1) July 5, 2021
A video screen grab while typing my name & my brothers name in the Mwangwego script. (you can mute the audio 🙂
Done!…well, not really. This is how far I’ve managed to go, the base consonants & syllables can be accurately displayed while utilizing the Latin character code-points however, there are still more consonant onsets formed by adding non-spacing modifiers and diacritics. These will require an equally simple but different shaping method which I’m still experimenting on.
The method I devised for inputting the base consonants & syllables comes with it’s own disadvantages as well, all scenarios considered. A user can mistakenly omit any of vowels [e i o u] because when they enter the initial consonant in a syllable cluster, the base consonant with a default vowel ‘a’ is always displayed & only changes when the modifying vowel is added into the sequence. Not so accurate after all. Looks like I have some more feature writing to do!








