Build Design Systems With Penpot Components
Jul 21, 2:15 AM
Penpot's new component system for building scalable design systems, emphasizing designer-developer collaboration.
smashingmagazine.com
medium bookmark / Raindrop.io |
CTO and Head of Research & Design at TOPBOTS, a strategy & research firm for enterprise artificial intelligence.

This popular internet meme demonstrates the alarming resemblance shared between chihuahuas and muffins. These images are commonly shared in presentations in the Artificial Intelligence (AI) industry (myself included).
But one question I haven’t seen anyone answer is just how good IS modern AI at removing the uncertainty of an image that could resemble a chihuahua or a muffin? For your entertainment and education, I’ll be investigating this question today.

Binary classification has been possible since the perceptron algorithm was invented in 1957. If you think AI is hyped now, the New York Times reported in 1958 that the invention was the beginning of a computer that would “be able to walk, talk, see, write, reproduce itself and be conscious of its existence.” While perceptron machines, like the Mark 1, were designed for image recognition, in reality they can only discern patterns that are linearly separable. This prevents them from learning the complex patterns found in most visual media.
No wonder the world was disillusioned and an AI winter ensued. Since then, multi-layer perceptions (popular in the 1980s) and convolutional neural networks (pioneered by Yann LeCun in 1998) have greatly outperformed single-layer perceptions in image recognition tasks.
With large labelled data sets like ImageNet and powerful GPU computing, more advanced neural network architectures like AlexNet, VGG, Inception, and ResNet have achieved state-of-the-art performance in computer vision.
If you’re a machine learning engineer, it’s easy to experiment with and fine-tune these models by using pre-trained models and weights in either Keras/Tensorflow or PyTorch. If you’re not comfortable tweaking neural networks on your own, you’re in luck. Virtually all the leading technology giants and promising startups claim to “democratize AI” by offering easy-to-use computer vision APIs.
Which one is the best? To answer this question, you’d have to clearly define your business goals, product use cases, test data sets, and metrics of success before you can compare the solutions against each other.
In lieu of a serious inquiry, we can at least get a high-level sense of the different behaviors of each platform by testing them with our toy problem of differentiating a chihuahua from a muffin.
To do this, I split the canonical meme into 16 test images. Then I use open source code written by engineer Gaurav Oberoi to consolidate results from the different APIs. Each image is pushed through the six APIs listed above, which return high confidence labels as their predictions. The exceptions are Microsoft, which returns both labels and a caption, and Cloudsight, which uses human-AI hybrid technology to return only a single caption. This is why Cloudsight can return eerily accurate captions for complex images, but takes 10–20 times longer to process.
Below is an example of the output. To see the results of all 16 chihuahua versus muffin images, click here.
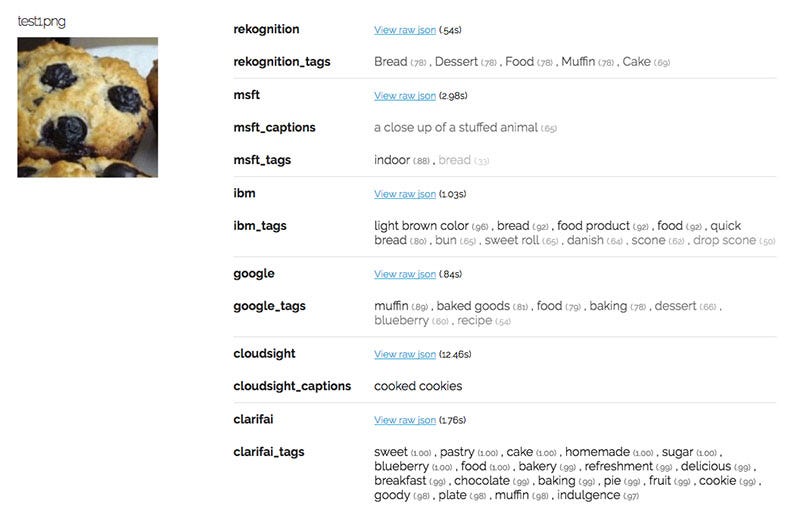
How well did the APIs do? Other than Microsoft, which confused this muffin for a stuffed animal, every other API recognized that the image was food. But there wasn’t an agreement about whether the food was bread, cake, cookies, or muffins. Google was the only API to successfully identify muffin as the label that is most probable.
Let’s look at a chihuahua example.

Again, the APIs did rather well. All of them realized that the image is a dog, although a few of them missed the exact breed.
There were definite failures, though. Microsoft returned a blatantly wrong caption three separate times, describing the muffin as either a stuffed animal or a teddy bear.
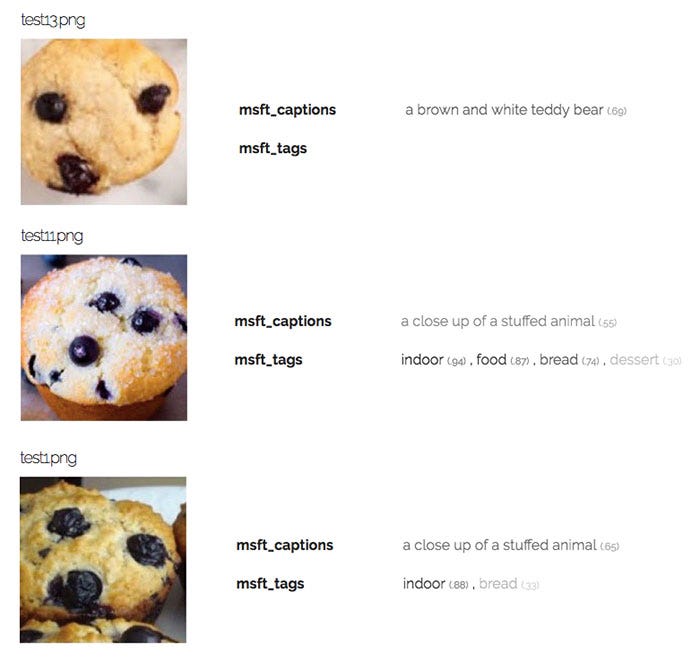
Google was the ultimate muffin identifier, returning “muffin” as its highest confidence label for 6 out of the 7 muffin images in the test set. The other APIs did not return “muffin” as the first label for any muffin picture, but instead returned less relevant labels like “bread”, “cookie”, or “cupcake.”
However, despite its string of successes, Google did fail on this specific muffin image, returning “snout” and “dog breed group” as predictions.

Even the world’s most advanced machine learning platforms are tripped up by our facetious chihuahua versus muffin challenge. A human toddler beats deep learning when it comes to figuring out what’s food and what’s Fido.
I’d like to know how well the APIs perform on real-world images of chihuahuas and muffins, and not just on ones where they are carefully curated to resemble each other. ImageNet happens to have 1750 images of chihuahuas and 1335 images of various types of muffins.
Some of the images were pretty easy for our APIs to recognize because the chihuahuas exhibit very distinct class features, such as bulging eyes and pointy ears. Such is the case of this chihuahua.
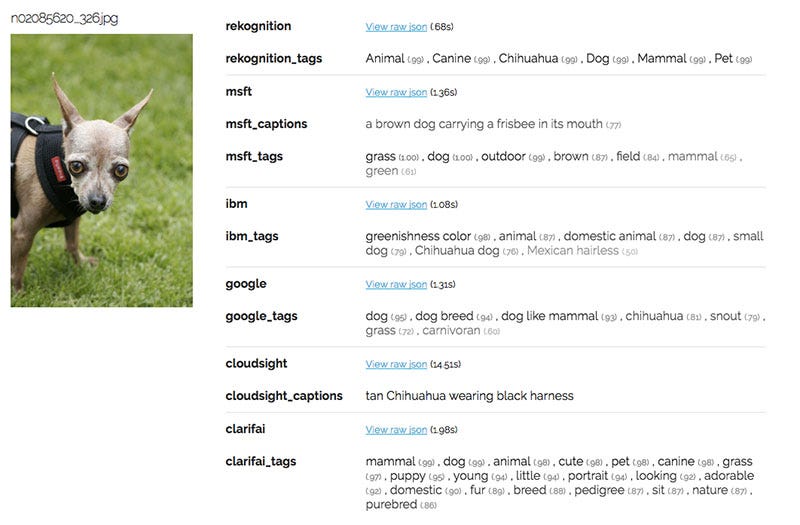
On the other hand, some images proved tricky. APIs often misidentify objects if there are multiple subjects within the same photo or if the subject is costumed or obstructed.
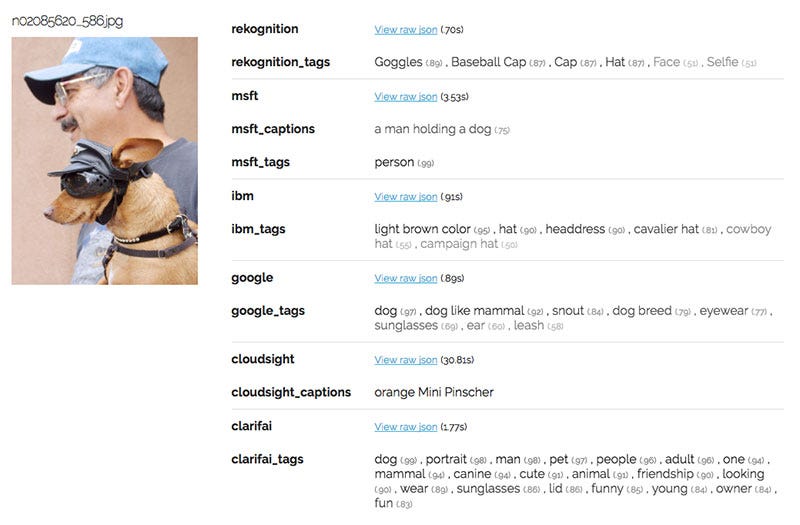
In the above image, the costume on the dog may have prevented the APIs (and likely many human classifiers) from correctly identifying the breed. IBM Watson manages to tag the hats but not the dog or the person wearing them.
With unstructured real-world data, including images, human-tagged labels are not always “ground truth.” Labels can be incorrect or “noisy.” Here’s an example of an image that was included in the “muffin” category on ImageNet.

Humans would likely identify this “muffin in disguise” more accurately as a “cupcake.” Fortunately, many of our APIs did return “cake”, “cupcake”, or “cookie” as predictions that are more relevant than the ImageNet category. Cloudsight’s human labelling produced the most accurate result of “cookie monster cupcake,” which is indeed a strange human invention for machines to interpret.
Using multiple models and APIs could be one interesting way to assess the “noisiness of labels.” In the case of ImageNet’s “muffin” category, the muffin varieties (eg., bran, corn, and popover) can appear visually distinct. Many are actually mislabelled as cupcakes or other non-muffin types of baked goods.

Running a large number of images through different image recognition APIs, and tracking the common overlaps and divergent one-offs can help you systematically flag images which might have noisy or incorrect labels.
Weird side note: In searching for different muffin categories on ImageNet, I came across an unexpected category called “muffin man,” which ImageNet defines as “formerly an itinerant peddler of muffins.” If you’re ever looking for photos of dudes presenting muffins, now you know where to go.

Just for fun, I tried to fool the APIs with tricky photos that contained:
Here’s how the APIs did on one of the photos featuring both a chihuahua AND a muffin:
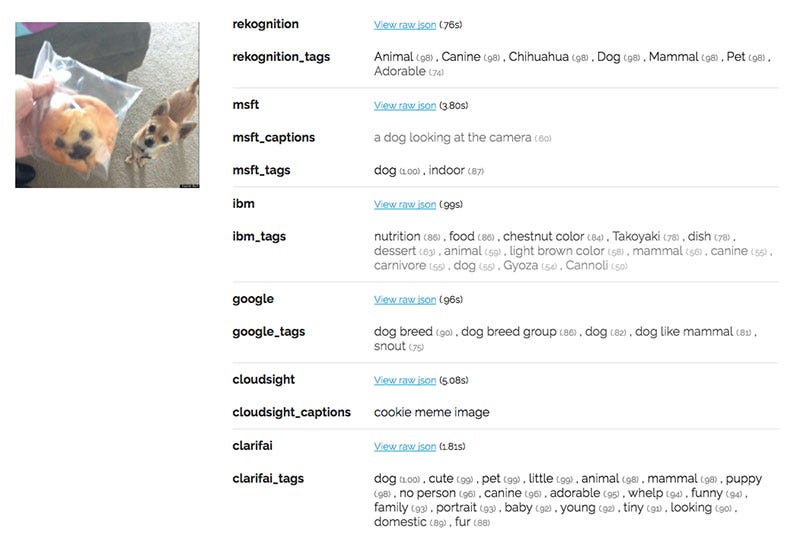
IBM and Cloudsight were the only two APIs that acknowledged any food was present in the image. IBM, however, was creative with its guesses of “takoyaki”, “gyoza”, and “cannoli.”
There was also confusion caused by the dog-shaped cupcakes:
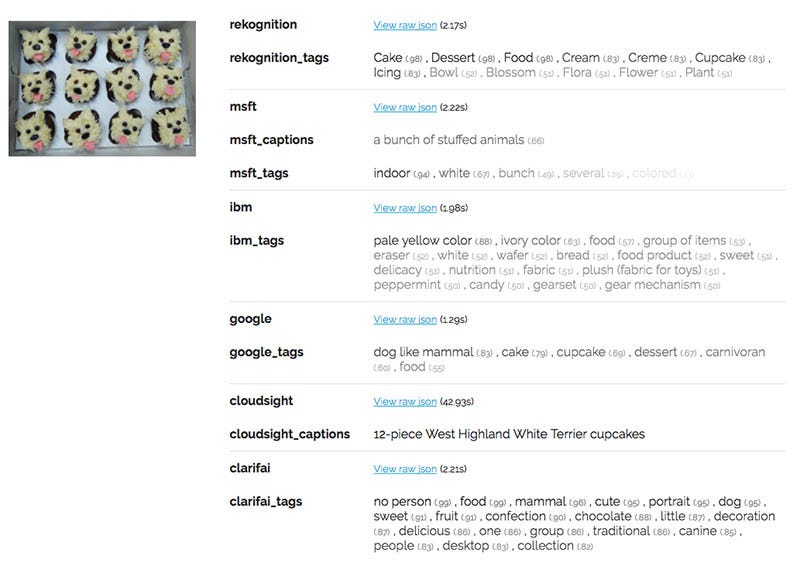
In typical fashion, Microsoft captioned the image as “a bunch of stuffed animals.” Google predicted that the photo was probably a “dog-like mammal” (0.89) than a “cake” (0.79). Clarifai thought with high confidence that the image contained both “food” (0.99) and a “mammal” (0.96).
In these complex or unusual cases, Cloudsight’s human captioning demonstrated superior results. Cloudsight tagged the last image as “12-piece West Highland White Terrier cupcakes.” And it recognized the former image as a popular meme.
While we can’t determine conclusively that one API is better than another by using these joke examples, you can definitely observe qualitative differences by how they perform.
Amazon’s Rekognition is not just good at identifying the primary object but also the many objects around it. For example, a human, bird, or piece of furniture when it is also in the image. Rekognition also includes qualitative judgements, such as “cute” or “adorable.” There’s a nice balance of objective and subjective labels in its top predictions.
Google’s Vision API and IBM Watson Vision are both very literal. They never seem to return labels other than straightforward, descriptive labels. The performance seems comparable between the two, with IBM typically returning slightly more labels on average for any given photo.
Microsoft’s tags were usually too high level. For example, “dog”, “canine”, and “mammal” were never once specified as a “chihuahua” or “muffin.” This a surprise. Microsoft also seemed to be very trigger happy with identifying muffins as “stuffed animals” in its auto-generated captions. You’d think ResNet would perform better, but this may be a quirk of this dataset, so I encourage you to do more robust testing on your own.
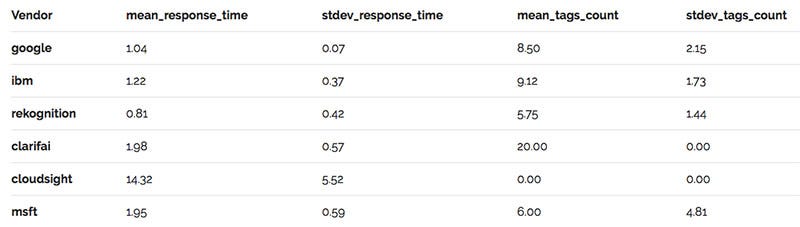
Cloudsight is a hybrid between human tagging and machine labelling. This API is much slower than the others, as you can see from the speed stats below. That said, for difficult or strange photos, Cloudsight’s description tends to be the most accurate, for example “12-piece West Highland White Terrier cupcakes.”
Clarifai returns, by far, the most tags (at 20). Yet not once did it correctly identify the breed of the dog as a “chihuahua.” Instead it resorted to more generic tags like “dog”, “mammal”, or “animal.” What Clarifai does do well is add qualitative and subjective labels, such as “cute”, “funny”, “adorable”, and “delicious.” It also returns abstract concepts like “facial expression” or “no person.” These can be useful if you’re looking for a richer description of images to be used in advertising or other consumer-facing purposes.
As stated before, to assess these APIs, you need to define clear business and product goals, an appropriate test data set, and metrics for success. You’d also need to consider factors such as cost, speed, and number of tags returned.
Here’s the summary for these additional metrics based on the 16 images from the classic chihuahua versus muffin meme. Amazon Rekognition regularly performs slightly faster than the other fully automated APIs. Cloudsight, as expected, is slower because of the human/AI hybrid structure, and only returns a single caption. Clarifai returns 20 labels by default.
Pricing for all of the APIs can be found on their pricing pages, which are linked below. Most of the APIs offer a free tier and then charge based on a monthly processing volume. At the time of the writing of this article, the approximate starting prices are as listed below, based on a per image rate. Prices are constantly in flux, so check for updates before you commit to any platform.
Many of the APIs charge between $0.001 and $0.002 per image if you purchase a few million images. Cloudsight is notably more expensive at $0.02 an image, with pricing based on 30,000 images per month. Its lower volume package can charge up to $0.07 an image!
If you would like to conduct your own unscientific, yet wildly entertaining, research into image recognition APIs, it may be helpful to know that the chihuahua versus muffin meme originator, Karen Zack, made a ton of “food versus animal” comparisons that are ripe for API benchmarking!
These are some of my favorites:

Have fun & let me know your results in the comments below!
If you enjoyed reading this article, join the TOPBOTS community to get the best bot news and exclusive industry content.
AI-driven updates, curated by humans and hand-edited for the Prototypr community